摘要
通过在对偶变量上引入一个额外的平均步骤,我们提出了求解强凸复合优化问题的广义Frank-Wolfe方法的一个简单变体。我们证明,在这种变体中,可以选择一个简单的常数步长,并获得对偶间隙上的线性收敛速率。通过对该变量的收敛性分析,我们分析了逻辑虚拟游戏算法的局部收敛率,该算法在博弈论中已经建立,但缺乏任何形式的收敛率保证。我们证明,在一定的期望对偶间隙下,该算法有很高的概率以0 (1/t)的速率局部收敛。
1 介绍
给定两个有限维实赋范空间和,对偶空间分别用和表示,我们考虑以下凸优化问题:
(P)式中为(有界)线性算子,是一个梯度为L-Lipschitz on(对于某些)的凸可微函数,即:
(1.1)是具有非空定义域的闭凸函数,表示为。我们假设h是“简单的”,使得“广义”线性优化子问题,即
(如果)可以很容易地解决任何问题。例如,如果h是多面体的指示函数,那么(GLO)就是一个线性规划,它的最优解是顶点。

涉及计算f的梯度并以(GLO)的形式解决子问题的一阶方法称为广义Frank-Wolfe (GFW)方法,如算法1所示。这种方法已经在之前的几部作品中进行了研究,例如Bach [1], Nesterov [2], Ghadimi[3]和Pena[4](我们将在1.1节中简要回顾所有这些作品)。事实上,GFW方法的名称来源于它可以被看作是Frank-Wolfe (FW)方法[5]的推广,该方法可以追溯到20世纪50年代(参见[6]及其参考文献)。具体地说,如果h是某“简单”凸紧集的指示函数(在该凸紧集下(GLO)易于求解),则GFW方法精确地专门化于FW方法。
1.1 计算复习GFW方法的最后保证
当h为非强凸时,GFW方法(即算法1)的计算保证与经典FW方法完全相同(如[6])。具体来说,假设是有界的,定义的直径为
此外,对于所有人,让我们定义原始最优性差距
然后是FW-gap
(1.2)事实上,很容易看出:
- (i)
对于所有(参见[7,式(2.4)]),
- (2)
的值是相同的(参见算法1中的第1步),因此在(1.2)中的特定选择无关紧要。
通过选择自适应步长或预先确定的步长,可以表明(例如,[1,第4节])
(1.3)接下来,让我们考虑h是强凸的情况(对于某些),即
与研究得很好的非强凸情况相比,强凸情况下GFW方法(即算法1)的计算保证似乎研究得较少。Nesterov [2, Sect. 5]表明,它与直径有界
然后为所有的步长选择预定的步长
(1.4)为(P)的条件数,为的算子范数。随后,Ghadimi[3,推论1(b)]表明,在不假设有界性的情况下,只要选择步长为常数,则最小fw -gap序列[cf.(1.3)]线性收敛于零:
(1.5)此外,Ghadimi[3,推论2]表明,如果通过某种回溯线搜索过程选择步长,则(1.5)中的收敛速率继续保持(直到绝对常数)。最近,Pena[4]表明,通过精确线搜索选择步长,我们有以下更简单的线性收敛结果:
(1.6)在哪里
(1.7)式(1.7)中,和分别表示f和h的Fenchel共轭,和表示的伴随函数(详见第2节)。此外,Pena[4,定理2]表明,(1.6)仍然成立(直到绝对常数),如果步长是通过回溯线搜索选择的。

1.2 主要贡献
在这项工作中,我们专注于h是-强凸(对于某些)的情况,并在算法2中提出了GFW方法的一个简单变体(参见算法1)。与算法1相比,我们看到它只是在对偶迭代中增加了一个额外的平均步骤(参见步骤3),并且平均的权重精确地由原始步长给出。因此,原始迭代和对偶迭代以“对称”方式更新。尽管这个额外的“对偶平均”步骤很简单,正如我们将在第3节中展示的那样,它允许我们通过简单地选择步长为常数(仅取决于条件数)来建立一个简单而优雅的对原始对偶对的对偶间隙序列的收缩。与算法1[2,3,4]中为GFW方法建立的先前结果相比,我们的结果表明,算法2具有简单选择步长的优点,它不涉及任何形式的线搜索-当条件数[cf.(1.4)]明确已知或易于估计时,这一特征特别有吸引力。
作为这项工作的第二个主要贡献,我们分析了逻辑虚拟游戏(LFP)算法的局部收敛率[8],这是一种经典的随机博弈论算法,仅被证明是渐近收敛的。我们分析的关键是观察到LFP的确定性版本(D-LFP)是算法2的一个特殊实例,LFP可以看作是D-LFP的某个“随机逼近”。因此,通过将LFP中的“随机噪声”适当地结合到D-LFP的分析中(这正是算法2的分析),我们得到了LFP的局部收敛速率。我们的分析表明,LFP在一定的期望对偶性间隙下,以高概率以0 (1/t)的速率局部收敛。有些令人惊讶的是,我们关于LFP经验行为的数值结果与我们的理论非常一致。
符号。对于任何非空集合,我们将其相对内部表示为。另外,让表示它的指示函数(即if和else)。对于矩阵M和任意,我们定义它的(p, q)-算子范数为。
2 预赛
让我们提供一些对偶理论的背景,这将有助于我们在第3节的分析。在本工作的其余部分,为了符号的简洁,我们将省略规范的下标,和的含义可以从上下文中推断出来。
首先,让我们先写出与(P)相关的(Fenchel)对偶问题:
(D)式中,表示的伴随函数,和分别表示f和h的Fenchel共轭函数:
(2.1) (2.2)从标准结果(例如,[9]),我们知道
- (i)
在以下意义上,函数是(1/L)-强凸on:
(2.3)的次可微点的集合。
- (2)
函数在上是凸可微的,在上是-Lipschitz。
此外,由[10,定理3.51]可知(P)与(D)之间存在强对偶性,即。接下来,让我们定义二象性差距为
(2.4)使用Fenchel对偶的标准结果(例如,[1]),我们可以看到,
(2.5)其中和的定义见(1.2)。换句话说,对于所有的,(2.5)意味着在x处的对偶间隙等于在x处的fw间隙。
目录
摘要 1 介绍 2 预赛 3.有限公司 算法2的收敛速度 4 申请LFP 5 初步实验研究 参考文献 致谢 作者信息 引理4.2的证明 搜索 导航 #####3.有限公司算法2的收敛速度
我们用下面的定理推导出算法2的(全局)收敛速度。
定理3.1
在算法2中,如果我们选择所有,那么
(3.1)式中为(P)的条件个数[cf.(1.4)],定义线性速率函数为
(3.2)证明
首先,从步骤1中的定义中,我们看到
因此,由(2.2)式的定义可知
(3.3)因为f和分别在和上有利普希茨梯度,我们有
(3.4) (3.5)另外,通过h和在各自定义域上的凸性,我们得到
(3.6) (3.7)结合式(3.4)-式(3.7)得到
(3.8)自
(3.9)我们看到了
(3.10)将式(3.3)和式(3.10)代入式(3.11),我们看到
(3.11)由h在定义域上的-强凸性,由步骤1和(3.3)中的定义,我们得到
(3.12)此外,使用(2.3)、(3.9)和(3.10)意义上的(1/L)强凸性,我们有
(3.13)将式(3.12)和式(3.13)代入式(3.11),得到
(3.14)如果我们选择,那么我们就会看到所有人。
话3.1
注意,在定理3.1中,线性速率函数是连续的、凹的、严格递增的。因此,条件数越小,线性速率越好。在这个体系中,我们有,因此,要找到一个原始对偶对,它只需要
(3.15)4 申请LFP
LFP算法(即random virtuyplay with best logit response),由Fudenberg和Kreps于1993年首次提出[8],是博弈论中的经典算法(参见[11]及其参考文献)。在这项工作中,我们关注的是二人零和版本,如算法3所示。具体来说,玩家I和II分别被给予有限的行动空间和[m],以及一个收益矩阵。一开始,玩家I和II分别选择了他们的初始行动和,他们的初始“行动历史”分别用和表示(其中表示第I个标准坐标向量)。在任何时候,为了让参与人I选择下一个行动,她首先根据参与人II的行动历史计算最佳对数-响应分布:
(4.1)在哪里
(4.2)为上定义的(负)熵函数,为-维概率单纯形,为正则化参数。然后,基于,她通过抽样从分布中随机选择,使得为。在获得之后,她通过和的凸组合从to更新她的行动历史:
(4.3)哪里可以解释为玩家I的“步长”,并且需要满足
(4.4)对于参与人II,其行动历史的更新与参与人I是对称的。具体来说,基于参与人I的行动历史,她计算出她的最佳对数-响应分布为
(4.5)在哪里
(4.6)是(负)熵函数定义在。然后她采样下一个动作,并更新她的动作历史,如下所示:
(4.7)
在文献中,LFP(即算法3)的渐近收敛性已经得到了很好的研究。例如,Hofbauer和Sandholm[12]证明了以下定理:
定理4.1
(Hofbauer和Sandholm[12,定理6.1(ii)])考虑不动点方程
(4.10)以及它的唯一解。然后在算法3中,对于任何初始化和,以及任何步长满足(4.4),我们有
(4.11)
然而,与对LFP的渐近收敛的充分理解相反,LFP的收敛速度在很大程度上是未知的。本节的目的是对LFP进行局部收敛率分析,并证明LFP在高概率下以0 (1/t)的速率局部收敛,其中收敛性是用一定的期望对偶间隙来衡量的。为此,让我们首先考虑算法4中所示的D-LFP(即LFP的确定性版本),并将其与算法2联系起来。
4.1 D-LFP与算法2的关联
让我们观察一个简单但重要的事实,即D-LFP(即算法4)是算法2的一个实例,用于解决以下(P)的实例:
(P-LFP)其中表示A的第j行,线性算子,和
(4.14)因此,(P-LFP)的对偶问题为:
(D-LFP)其中表示A的第i列(对于)。因此,根据(2.4),对偶间隙有如下形式
(4.15)现在,为了看到(P- lfp)是(P)的一个实例(这反过来意味着(D- lfp)是(D)的一个实例),注意到这一点就足够了
- (i)
(4.14)中给出的函数f在上是凸可微的,并且在上是-Lipschitz,即
(4.16)(要看到这一点,请注意,
- (2)
函数是-强凸的,即,
(详见[13,引理3])
此外,为了看到D-LFP(即算法4)是算法2的一个实例,我们简单地注意到,对于所有(i)和(ii),从f在(4.14)中的定义,
(4.17)因此。因此,如果我们按照与定理3.1相同的方式选择步长,即(P-LFP)的条件数,我们看到D-LFP在(3.1)中也具有与算法2相同的线性收敛速率。(回想一下,它表示A的-算子范数,并且由其中表示A的(j, i)项给出,对于和。)
4.2 当地的公司LFP的收敛率分析
现在,让我们分析LFP(即算法3)的局部收敛率,将其视为D-LFP的某个“随机逼近”。具体来说,我们可以将算法3中的迭代(4.8)和(4.9)重写为
(4.18) (4.19)注意,和可以看作是分别由采样步长和产生的随机误差。实际上,我们可以很容易地看出,误差序列和是鞅差分序列。形式上,让我们定义一个过滤,对于所有,即由一组随机变量产生的-域。然后我们有
(4.20)接下来,让我们注意到,由于(参见定理4.1),存在这样的半径,其中
为了表示方便,我们写成,它是的紧邻域它远离的相对边界。这个邻域将在LFP的局部收敛速率分析中发挥重要作用。这个邻域的优点可以从下面的引理中看出。
引理4.1
存在有限的常数,使得
(4.21) (4.22)证明
事实上,我们可以确定哪个是有限的,因为它在紧集合上是连续的。类似地,我们可以设。
此外,让我们做另一个重要的观察:对于任何初始动作和,以及满足(4.4)中条件的任何步长,LFP(即算法3)产生的序列最终都有很大的概率位于(4.4)中。事实上,这是定理4.1的一个简单推论,说明如下。
推论4.1
定义事件的顺序,以便
(4.23)如果步长满足(4.4),则对于任意,存在这样的
证明
实际上,从标准结果(例如,[14,定理3.3])中,我们知道(4.11)中几乎肯定的收敛结果等价于。因此,对于任何一个人,存在这样的情况,对于所有人,。这就完成了证明。
最后,我们的分析需要以下技术引理,其证明遵循标准技术(参见例如,[6,第3节])。为了完整起见,我们在附录A中提供了证明。
引理4.2
设为满足以下递归的非负序列:
(4.24)在哪里,为所有人。如果我们为所有人选择,那么我们就拥有了
(4.25)有了以上的结果,我们就可以分析LFP的局部收敛速度了。事实上,我们对LFP的分析修改了D-LFP的分析(即算法2),通过适当处理分别出现在(4.18)和(4.19)中的随机误差和。在给出我们的结果之前,让我们首先注意到(4.15)中的对偶间隙是联合连续的,因此我们可以定义它的最大值为
(4.26)定理4.2
(LFP的局部收敛率)。在算法3中,选择所有初始动作和和。那么对于任意,存在这样的和
(4.27)其中,和分别满足(4.21)和式(4.22)。
证明
由于步长满足式(4.4)中的条件,由推论4.1可知存在这样的条件。现在,通过对事件的条件反射,我们看到所有的。因此,使用(4.21),我们得到:
(4.28) (4.29)式中(4.28)由式(4.18)和中的定义推导而来,式(4.29)由的凸性推导而来。类似地,我们有
(4.30)此外,由(P-LFP)和(D-LFP)可知,f和分别在和上与-Lipschitz梯度可微,因此
(4.31) (4.32)这里我们使用and(参见第4.1节)。因此,通过结合(4.29)-(4.32),并分别使用(P-LFP)和(D-LFP)中的定义和,我们有
(4.33)既然和,我们知道
(4.34)由式(4.33),式(4.34)和式(4.20),我们知道
(4.35)最后,将引理4.2应用于式(4.35)并使用式(4.26)中的定义,我们完成了证明。
5 初步实验研究
我们比较了前面提到的几种求解(P-LFP)问题的方法的数值性能。这些方法包括
- (i)
GFW- n: Nesterov [2, Sect. 5]中逐步减小步长的GFW方法(即算法1)。具体来说,是为了。
- (2)
GFW- g: Ghadimi中具有恒定步长的GFW方法(即算法1)[3,推论1(b)]。具体来说,for, where。
- (3)
GFWDA:算法2(或等价的算法4),步长为定理3.1中的常数。具体来说,for, where。
- (iv)
LFP:步长递减的算法3,如定理4.2。具体来说,是为了。
为了生成数据矩阵A,我们选择维数和,并独立于区间上的均匀分布生成A的每一项。此外,我们选择。对于我们实验中使用的A的具体实例,我们有and因此
注意,以上四种方法中的每一种都能够产生收敛于零的对偶间隙序列。其中,GFW-N和GFW-G产生的序列为[cf. (1.3)], GFWDA和LFP产生的序列为[cf.(2.4)]。因此,我们将使用这些对偶间隙的收敛速度作为比较标准。对于起始点,我们选择所有四种方法。此外,对于GFWDA,我们选择,使GFW-N、GFW-G和GFWDA具有相同的初始二元性间隙,即。对于LFP,因为我们需要选择一些(参见算法3),我们让。请注意,与由。给出的相比,这个选择将导致更大的二元性差距。然而,在我们的实验中,我们观察到差异并不显著。
实验结果我们在对数线性和对数对数尺度下绘制了所有四种方法与迭代产生的对偶间隙图1。由于LFP是一种随机算法,我们重复运行它10次(与上述相同的起点),并绘制平均对偶间隙轨迹。从图1中,我们可以观察到以下几点。首先,GFWDA和LFP分别是四种方法中最快和最慢的。事实上,GFWDA在不到15次迭代中产生了顺序的对偶性差距,而LFP在前30次迭代中几乎没有任何进展。其次,GFW-N以亚线性速度收敛,其收敛速度远快于理论推导[cf.(1.4)]。这可能是因为(P-LFP)具有某些有利于GFW-N的结构特性(除了平滑性和强凸性)。第三,虽然GFWDA和GFW-G都是线性收敛,但GFW-G的线性速度比GFWDA慢。这与我们的理论分析是一致的。具体来说,GFW-G的线性速率为[cf.(1.5)],比GFWDA的线性速率慢,即(cf.定理3.1)。
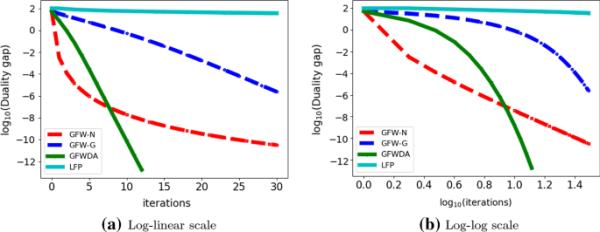
比较GFW-N、GFW-G、GFWDA和LFP在对数-线性尺度和b对数-对数尺度下产生的对偶间隙的收敛速度
.jpg)
LFP生成的平均对偶间隙轨迹的对数-对数图
接下来,让我们检查LFP的局部收敛速度。从图2中可以看出,从大约100次迭代开始,收敛速度为0 (1/t)。为了更好地说明,在表1中,我们以对数尺度计算该图在恒定长度的迭代间隔上的斜率。从表1中我们可以清楚地看到,斜率的幅度最初非常小,这对应于对偶间隙的缓慢初始收敛。然而,它们逐渐收敛于1,这对应于定理4.2中“预测”的O(1/t)局部收敛率。
下载原文档:https://link.springer.com/content/pdf/10.1007/s11590-022-01951-0.pdf






